Methods
Pre-Processing
Aside from merging the datasets as previously mentioned, there was little data-preprocessing that we implemented. We used a named entity recognition (NER) model to extract the key ingredients from each recipe, removing the redundency descriptions and measurements. For example, an ingredient listed as "1 (10 ounce) can prepared pizza crust" will be parsed into "pizza crust". In this way it improves the performance of our keyword analysis (TF-IDF) algorithm.
Object Detection Model
The model we used to determine individual ingredients in an image is the GPT-4 Vision model. We also tried two open source models, ResNet-50 and YOLO, however, GPT-4 performed significantly better. GPT-4 is able to accurately identify almost every ingredient in the images we have tested. However, a limitation of the model is that it is unable to detect the quantity of ingredients present other than counting.
Search
We tested 3 different options for our search model: semantic search, TF-IDF, and exact keyword matching, and evaluated them qualitatively. We compared how each search algorithm performed by comparing the ingredients in the recipe returned against our list of input ingredients. From our tests, we found that semantic search made too many assumptions about our inputs, and returned recipes used our ingredients, but also required many other ingredients that were not included in the input. Using exact keyword matches seemed to have to opposite effect; the recipes returned matched our input, but were extremely simple, often being beverages that only required 2-3 ingredients.
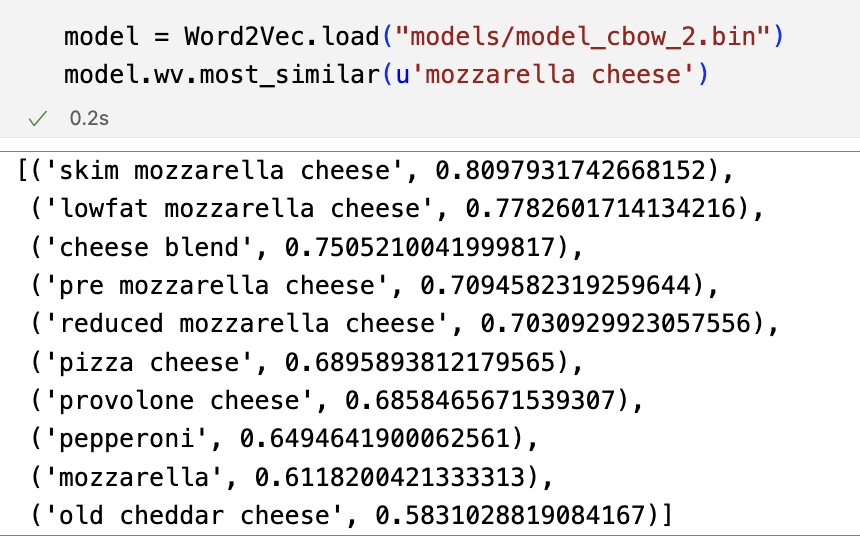
TF-IDF was in the middle of the spectrum: the recipes matched our input list, but made some inappropriate ingredient substitutions. For instance, cream cheese in a cheese cake recipe should not be replaced with cheddar. In order to correct for this effect, we trained a Word2Vec embedding that captures distributional similarities between words. That is, words that often appear in similar contexts are mapped to vectors separated by a shorter Euclidean distance (the L2 norm). In our case, the words here are recipe ingredients. The following is one example: mozzarella cheese, which is most commonly used in pizza, is considered similar with other pizza-related cheese and ingredients.
Retrieval Augmented Generation with LangChain
Our final part invovles using LLMs to support conversations with user. LangChain is a framework for deploying LLMs for applications, and in our case, the context-aware generation. The top related recipes retrieved from our search, as well as their descriptions, will be injected into the LLM (GPT-3.5-turbo) as reference when answering questions and fulfilling users' requirements. The store and load of chat history is one of the biggest challenges in implementing this feature. We currently achieved it by using ConversationBufferMemory from the LangChain memory library.